Using SQLAthanor¶
- Introduction
- SQLAthanor Features
- Overview
- 1. Installing SQLAthanor
- 2. Import SQLAthanor
- 3. Define Your Models
- 4. Configure Serialization/De-serialization
- 5. Configuring Pre-processing and Post-processing
- 6. Serializing a Model Instance
- 7. Deserializing Data
- Using Declarative Reflection with SQLAthanor
- Using Automap with SQLAthanor
- Generating SQLAlchemy Tables…
Introduction¶
What is Serialization?¶
“Serialization” is a common short-hand for two important concepts: serialization and de-serialization.
To over-simplify, serialization is the process of taking an object in one programming language (say, Python) that can be understood by one program (say, yours) and converting it into a format that can be understood by a different program, often written in a different programming language (say, JavaScript).
De-serialization is the exact same process - but in reverse. It takes data in another format, often from another program, and converts it into an object that your program can understand.
So why is it important? Well, because modern programming is all about communication. Which in this context means communication between different programs, APIs, microservices, etc. And these various programs and microservices may be written in vastly different programming languages, have (often different) approaches to security, etc. Which means they need to be able to talk to each other appropriately.
Which is where serialization and de-serialization come in, since they’re the process that makes that communication possible.
In a very typical example, you can imagine a modern web application. The back-end might be written in Python, maybe using a framework like Flask or Django. The back-end exposes a variety of RESTful APIs that handle the business logic of your web app. But you’ve got an entirely separate front-end, probably written in JavaScript using React/Redux, AngularJS, or something similar.
In most web applications, at some point your back-end will need to retrieve data from a database (which an ORM like SQLAlchemy is great at), and will want to hand it off to your front-end. A typical example might be if you want to list users, or in a social media-style app, list a user’s friends. So once your Python back-end has gotten a list of users, how does it communicate that list to your JavaScript front-end? Most likely by exchanging JSON objects.
Which means that your Python back-end needs to take the list of users it retrieved, convert their data into JSON format, and transmit it to the front-end. That’s serialization.
But now let’s say a user in your front-end changes their email address. The front-end will need to let the back-end know, and your back-end will need to update the relevant database record with the latest change. So how does the front-end communicate that change to the back-end? Again, by sending a JSON object to the back-end. But your back-end needs to parse that data, validate it, and then reflect the change in the underlying database. The process of parsing that data? That’s de-serialization.
Why SQLAthanor?¶
So if serialziation and de-serialization are so important, how does this relate to SQLAthanor? Well, serialization and de-serialization can be complicated:
- Different programs may need to serialize and de-serialize into and from multiple formats.
- Some data (like passwords) should only be de-serialized, but for security reasons should never be serialized.
- Serialization and de-serialization may need various pre-processing steps to validate the data or coerce it to/from different data types…and that validation/coercion logic may be different depending on the data format.
- The (fantastic) SQLAlchemy ORM handles database read/write operations amazingly, but does not include any serialization/de-serialization support.
This leads to a labor-intensive process of writing custom serialization/de-serialization logic for multiple (different) models and repeating that process across multiple applications. Better, we think, to package that functionality into a library.
Which is what SQLAthanor is.
It is designed to extend the functionality of the SQLAlchemy ORM with support for serialization and de-serialization into/from:
Which should hopefully save some effort when building applications that need to talk to the outside world (and really, don’t all apps do these days?).
SQLAthanor vs. Alternatives¶
Since serialization and de-serialization are common problems, there are a variety of alternative ways to serialize and de-serialize your SQLAlchemy models. Obviously, I’m biased in favor of SQLAthanor. But it might be helpful to compare SQLAthanor to some commonly-used alternatives:
Adding your own custom serialization/de-serialization logic to your SQLAlchemy declarative models is a very viable strategy. It’s what I did for years, until I got tired of repeating the same patterns over and over again, and decided to build SQLAthanor instead.
But of course, implementing custom serialization/de-serialization logic takes a bit of effort.
Tip
When to use it?
In practice, I find that rolling my own solution is great when it’s a simple model with very limited business logic. It’s a “quick-and-dirty” solution, where I’m trading rapid implementation (yay!) for less flexibility/functionality (boo!).
Considering how easy SQLAthanor is to configure / apply, however, I find that I never really roll my own serialization/de-serialization approach when working SQLAlchemy models any more.
Tip
Because Pydantic is growing in popularity, we have decided to integrate Pydantic support within SQLAthanor.
Using
generate_model_from_pydantic(),
you can now programmatically generate a SQLAthanor
BaseModel from your
Pydantic models.
This allows you to only maintain one representation of your data model (the Pydantic one), while still being able to use SQLAthanor’s rich serialization / de-serialization configuration functionality.
Pydantic is an amazing object parsing library that leverages native Python typing to provide simple syntax and rich functionality. While I have philosophical quibbles about some of its API semantics and architectural choices, I cannot deny that it is elegant, extremely performant, and all around excellent.
Since FastAPI, one of the fastest-growing web application frameworks in the Python ecosystem is tightly coupled with Pydantic, it has gained significant ground within the community.
However, when compared to SQLAthanor it has a number of architectural limitations:
While Pydantic has excellent serialization and deserialization functionality to JSON, it is extremely limited with its serialization/deserialization support for other common data formats like CSV or YAML.
Second, by its design Pydantic forces you to maintain multiple representations of your data model. On the one hand, you will need your SQLAlchemy ORM representation, but then you will also need one or more Pydantic models that will be used to serialize/de-serialize your model instances.
Third, by its design, Pydantic tends to lead to significant amounts of duplicate code, maintaining similar-but-not-quite-identical versions of your data models (with one Pydantic schema for each context in which you might serialize/de-serialize your data model).
Fourth, its API semantics can get extremely complicated when trying to use it as a true serialization/de-serialization library.
While Pydantic has made efforts to integrate ORM support into its API, that functionality is relatively limited in its current form.
Tip
When to use it?
Pydantic is easy to use when building simple web applications due to its reliance on native Python typing. The need to maintain multiple representations of your data models is a trivial burden with small applications or relatively simple data models.
Pydantic is also practically required when building applications using the excellent FastAPI framework.
So given these two things, we recommend using Pydantic in combination with SQLAthanor to get the best of both words: native Python typing for validation against your Python model (via Pydantic) with rich configurable serialization/de-serialization logic (via SQLAthanor), all integrated into the underlying SQLAlchemy ORM.
The Marshmallow library and its Marshmallow-SQLAlchemy extension are both fantastic. However, they have one major architectural difference to SQLAthanor and several more minor differences:
The biggest difference is that by design, they force you to maintain two representations of your data model. One is your SQLAlchemy model class, while the other is your Marshmallow schema (which determines how your model is serialized/de-serialized). Marshmallow-SQLAlchemy specifically tries to simplify this by generating a schema based on your model class, but you still need to configure, manage, and maintain both representations - which as your project gets more complex, becomes non-trivial.
SQLAthanor by contrast lets you configure serialization/deserialization in your SQLAlchemy model class definition. You’re only maintaining one data model representation in your Python code, which is a massive time/effort/risk-reduction.
Other notable differences relate to the API/syntax used to support non-JSON formats. I think Marshmallow uses a non-obvious approach, while with SQLAthanor the APIs are clean and simple. Of course, on this point, YMMV.
Tip
When to use it?
Marshmallow has one advantage over SQLAthanor: It can serialize/de-serialize any Python object, whether it is a SQLAlchemy model class or not. SQLAthanor only works with SQLAlchemy.
As a result, it may be worth using Marshmallow instead of SQLAthanor if you expect to be serializing / de-serializing a lot of non-SQLAlchemy objects.
The Colander library and the ColanderAlchemy extension are both great, but they have a similar major architectural difference to SQLAthanor as Marshmallow/Marshmallow-SQLAlchemy:
By design, they force you to maintain two representations of your data model. One is your SQLAlchemy model class, while the other is your Colander schema (which determines how your model is serialized/de-serialized). ColanderAlchemy tries to simplify this by generating a schema based on your model class, but you still need to configure, manage, and maintain both representations - which as your project gets more complex, becomes non-trivial.
SQLAthanor by contrast lets you configure serialization/deserialization in your SQLAlchemy model class definition. You’re only maintaining one data model representation in your Python code, which is a massive time/effort/risk-reduction.
A second major difference is that, again by design, Colander is designed to serialize/de-serialize Python objects to a set of Python primitives. Since neither JSON, CSV, or YAML are Python primitives, you’ll still need to serialize/de-serialize Colander’s input/output to/from its final “transmissable” form. Once you’ve got a Python primitive, this isn’t difficult - but it is an extra step.
Tip
When to use it?
Colander has one advantage over SQLAthanor: It can serialize/de-serialize any Python object, whether it is a SQLAlchemy model class or not. SQLAthanor only works with SQLAlchemy.
As a result, it may be worth using Colander instead of SQLAthanor if you expect to be serializing / de-serializing a lot of non-SQLAlchemy objects.
pandas is one of my favorite analytical libraries. It has a number of
great methods that adopt a simple syntax, like read_csv() or to_csv()
which de-serialize / serialize data to various formats (including SQL, JSON, CSV,
etc.).
So at first blush, one might think: Why not just use pandas to handle serialization/de-serialization?
Well, pandas isn’t really a serialization alternative to SQLAthanor. More properly, it is an ORM alternative to SQLAlchemy itself.
I could write (and have written) a lot on the subject, but the key difference is that pandas is a “lightweight” ORM that focuses on providing a Pythonic interface to work with the output of single SQL queries. It does not support complex relationships between tables, or support the abstracted definition of business logic that applies to an object representation of a “concept” stored in your database.
SQLAlchemy is specifically designed to do those things.
So you can think of pandas as being a less-abstract, “closer to bare metal”
ORM - which is what you want if you want very efficient computations, on
relatively “flat” (non-nested/minimally relational) data. Modification or
manipulation of the data can be done by mutating your pandas DataFrame
without too much maintenance burden because those mutations/modifications
probably don’t rely too much on complex abstract business logic.
SQLAthanor piggybacks on SQLAlchemy’s business logic-focused ORM capabilities. It is designed to allow you to configure expected behavior once and then re-use that capability across all instances (records) of your data. And it’s designed to play well with all of the other complex abstractions that SQLAlchemy supports, like relationships, hybrid properties, reflection, or association proxies.
pandas serialization/de-serialization capabilities can only be configured “at use-time” (in the method call), which leads to a higher maintenance burden. SQLAthanor’s serialization/de-serialization capabilities are specifically designed to be configurable when defining your data model.
Tip
When to use it?
The decision of whether to use pandas or SQLAlchemy is a complex one, but in my experience a good rule of thumb is to ask yourself whether you’re going to need to apply complex business logic to your data.
The more complex the business logic is, the more likely SQLAlchemy will be a better solution. And if you are using SQLAlchemy, then SQLAthanor provides great and easy-to-use serialization/de-serialization capabilities.
SQLAthanor Features¶
- Configure serialization and de-serialization support when defining your SQLAlchemy models.
- Automatically include serialization methods in your SQLAlchemy model instances.
- Automatically include de-serialization “creator” methods in your SQLAlchemy models.
- Automatically include de-serialization “updater” methods to your SQLAlchemy model instances.
- Support serialization and de-serialization across the most-common data exchange
formats: JSON,
CSV,
YAML, and Python
dict. - Support pre-processing before serialization/de-serialization for data validation or coercion.
- Support serialization and de-serialization for complex models
that may include: relationships,
hybrid properties,
association proxies, or standard Python
@property. - Simultaneously support different configurations for different serialization or de-serialization requirements.
- Maintain all of the existing APIs, methods, functions, and functionality of SQLAlchemy Core.
- Maintain all of the existing APIs, methods, functions, and functionality of SQLAlchemy ORM.
- Maintain all of the existing APIs, methods, functions, and functionality of SQLAlchemy Declarative ORM.
- Drive the definition and configuration of your data model from your Pydantic models.
Overview¶
SQLAthanor is designed to extend the fantastic SQLAlchemy library, to provide it with seamless serialization and de-serialization support. What do we mean by seamless? Well, in an ideal world we want serialization and de-serialization to work like this:
# To create serialized output from a model instance, just use:
as_json = model_instance.to_json()
as_csv = model_instance.to_csv()
as_yaml = model_instance.to_yaml()
as_dict = model_instance.to_dict()
# To create a new model instance from serialized data, just use:
new_as_instance = ModelClass.new_from_json(as_json)
new_as_instance = ModelClass.new_from_csv(as_csv)
new_as_instance = ModelClass.new_from_yaml(as_yaml)
new_as_instance = ModelClass.new_from_dict(as_dict)
# To update an existing model instance from serialized data, just use:
model_instance.update_from_json(as_json)
model_instance.update_from_csv(as_csv)
model_instance.update_from_yaml(as_yaml)
model_instance.update_from_dict(as_dict)
Even knowing nothing about SQLAlchemy or SQLAthanor, it should be pretty easy to figure out what’s happening in that code, right?
Well, that’s exactly what SQLAthanor does for you. So how? Let’s break that down.
How SQLAthanor Works¶
SQLAthanor is a drop-in replacement for SQLAlchemy.
What does this mean? It means that it’s designed to seamlessly replace some of
your SQLAlchemy import statements. Then, you can continue to define your
models just as you would using the
SQLAlchemy ORM - but now they’ll support
serialization and de-serialization.
In other words, the process of using SQLAthanor is very simple:
- Install SQLAthanor. (see here)
- Import the components used to define your model classes. (see here)
- Define your model classes, just as you would in SQLAlchemy. (see here)
- Configure which model attributes to be serialized (output) and de-serialized (input). (see here)
- Configure any pre/post-processing for serialization and de-serialization, respectively. (see here)
- Serialize your model instances as needed. (see here)
- Create new model instances using de-serialization. (see here)
- Update existing model instances using de-serialization. (see here)
And that’s it! Once you’ve done the steps above, you can easily serialize data from your models and de-serialize data into your models using simple methods.
Tip
Because SQLAthanor inherits from and extends SQLAlchemy, your existing SQLAlchemy models will work with no change.
By default, serialization and de-serialization are disabled for any model attribute unless they are explicitly enabled.
1. Installing SQLAthanor¶
To install SQLAthanor, just execute:
$ pip install sqlathanor
Dependencies¶
- SQLAlchemy v.0.9 or higher
- PyYAML v3.10 or higher
- simplejson v3.0 or higher
- Validator-Collection v1.4.0 or higher
- SQLAlchemy v.0.9 or higher
- PyYAML v3.10 or higher
- simplejson v3.0 or higher
- Validator-Collection v1.4.0 or higher
2. Import SQLAthanor¶
Since SQLAthanor is a drop-in replacement, you should import it using the same elements as you would import from SQLAlchemy:
The code below is a pretty standard set of import statements when
working with SQLAlchemy and its
Declarative ORM.
They’re provided for reference below, but do not make use of SQLAthanor and do not provide any support for serialization or de-serialization:
from sqlalchemy.ext.declarative import declarative_base, as_declarative
from sqlalchemy import Column, Integer, String # ... and any other data types
# The following are optional, depending on how your data model is designed:
from sqlalchemy.orm import relationship
from sqlalchemy.ext.hybrid import hybrid_property
from sqlalchemy.ext.associationproxy import association_proxy
To import SQLAthanor, just replace the relevant SQLAlchemy imports with their SQLAthanor counterparts as below:
from sqlathanor import declarative_base, as_declarative
from sqlathanor import Column
from sqlathanor import relationship # This import is optional, depending on
# how your data model is designed.
from sqlalchemy import Integer, String # ... and any other data types
# The following are optional, depending on how your data model is designed:
from sqlalchemy.ext.hybrid import hybrid_property
from sqlalchemy.ext.associationproxy import association_proxy
Tip
Because of its many moving parts, SQLAlchemy
splits its various pieces into multiple modules and forces you to use many
import statements.
The example above maintains this strategy to show how SQLAthanor is a
1:1 drop-in replacement. But obviously, you can import all of the items you
need in just one import statement:
from sqlathanor import declarative_base, as_declarative, Column, relationship
SQLAthanor is designed to work with Flask-SQLAlchemy too! However, you need to:
- Import the
FlaskBaseModelclass, and then supply it as themodel_classargument when initializing Flask-SQLAlchemy. - Initialize SQLAthanor on your
dbinstance usinginitialize_flask_sqlathanor.
from sqlathanor import FlaskBaseModel, initialize_flask_sqlathanor
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////tmp/test.db'
db = SQLAlchemy(app, model_class = FlaskBaseModel)
db = initialize_flask_sqlathanor(db)
And that’s it! Now SQLAthanor serialization functionality will be supported by:
- Flask-SQLAlchemy’s
db.Model - Flask-SQLAlchemy’s
db.relationship() - Flask-SQLAlchemy’s
db.Column
See also
For more information about working with Flask-SQLAlchemy, please review their detailed documentation.
As the examples provided above show, importing SQLAthanor is very straightforward, and you can include it in an existing codebase quickly and easily. In fact, your code should work just as before. Only now it will include new functionality to support serialization and de-serialization.
The table below shows how SQLAlchemy classes and functions map to their SQLAthanor replacements:
| SQLAlchemy Component | SQLAthanor Analog |
|---|---|
from sqlalchemy.ext.declarative import declarative_base
|
from sqlathanor import declarative_base
|
from sqlalchemy.ext.declarative import as_declarative
|
from sqlathanor import as_declarative
|
from sqlalchemy import Column
|
from sqlathanor import Column
|
from sqlalchemy import relationship
|
from sqlathanor import relationship
|
from sqlalchemy.ext.automap import automap_base
|
from sqlathanor.automap import automap_base
|
3. Define Your Models¶
Because SQLAthanor is a drop-in replacement for SQLAlchemy and its Declarative ORM, you can define your models the exact same way you would do so normally:
New in version 0.8.0.
If your application is using Pydantic as a parsing/validation library, then you
can programmatically generate a pre-configured
SQLAlchemy Declarative
model class using SQLAthanor with the syntax
generate_model_from_pydantic().
This function can accept one or more Pydantic models, and will consolidate them into a single SQLAthanor model class, with each underlying Pydantic model corresponding to a configuration set for easy serialization / deserialization:
from sqlathanor import generate_model_from_pydantic
# Assuming that "PydanticBaseModel" is a
PydanticDBModel = generate_model_from_pydantic([PydanticReadModel, PydanticWriteModel],
tablename = 'my_table_name',
primary_key = 'id')
SQLAlchemy supports the use of reflection with the SQLAlchemy Declarative ORM.
This is a process where SQLAlchemy automatically constructs a
Declarative
model class based on what it reads from the table definition stored in your
SQL database or a corresponding Table
instance already defined and registered with a
MetaData object.
SQLAthanor also supports the same pattern. For details, please see: Using Declarative Reflection with SQLAthanor
See also
- Using Declarative Reflection with SQLAthanor
- SQLAlchemy: Reflecting Database Objects
- SQLAlchemy: Using Reflection with Declarative
New in version 0.2.0.
The Automap Extension is an incredibly useful tool for modeling existing databases with minimal effort. What it does is it reads your existing database’s metadata and automatically constructs SQLAlchemy Declarative ORM model classes populated with your tables’ columns.
Neat, right? Saves a ton of effort.
Using SQLAthanor you can ensure that your automapped (automatically generated) models support serialization and de-serialization. For more details, please see: Using Automap with SQLAthanor.
See also
- Using Automap with SQLAthanor
- SQLAlchemy: Automap Extension
New in version 0.3.0.
If you have serialized data in either CSV,
JSON,
YAML, or a Python
dict, you can programmatically generate a
SQLAlchemy Declarative
model class using SQLAthanor with the syntax
generate_model_from_<format>() where <format> corresponds to csv,
json, yaml, or dict:
##### FROM CSV:
from sqlathanor import generate_model_from_csv
# Assuming that "csv_data" contains your CSV data
CSVModel = generate_model_from_csv(csv_data,
tablename = 'my_table_name',
primary_key = 'id')
##### FROM JSON:
from sqlathanor import generate_model_from_json
# Assuming that "json_string" contains your JSON data in a string
JSONModel = generate_model_from_json(json_string,
tablename = 'my_table_name',
primary_key = 'id')
##### FROM YAML:
from sqlathanor import generate_model_from_yaml
# Assuming that "yaml_string" contains your YAML data in a string
YAMLModel = generate_model_from_yaml(yaml_string,
tablename = 'my_table_name',
primary_key = 'id')
##### FROM DICT:
from sqlathanor import generate_model_from_dict
# Assuming that "yaml_string" contains your YAML data in a string
DictModel = generate_model_from_dict(dict_string,
tablename = 'my_table_name',
primary_key = 'id')
4. Configure Serialization/De-serialization¶
explicit is better than implicit
—PEP 20 - The Zen of Python
By default (for security reasons) serialization and de-serialization are disabled on all of your model attributes. However, SQLAthanor exists to let you explicitly enable serialization and/or de-serialization for specific model attributes.
Here are some important facts to understand for context:
- You can enable serialization separately from de-serialization. This allows you to do things like de-serialize a
passwordfield (expect it as an input), but never include it in the output that you serialize.- You can configure serialization/de-serialization differently for different formats. SQLAthanor supports CSV, JSON, YAML, and Python
dict.- You can serialize or de-serialize any model attribute that is bound to your model class. This includes:
- Attributes that correspond to columns in the underlying SQL table.
- Attributes that represent a relationship to another model.
- Attributes that are defined as hybrid properties.
- Attributes that are defined as association proxies.
- Instance attributes defined using Python’s built-in
@propertydecorator.
In general, SQLAthanor supports two different mechanisms to configure serialization/de-serialization: Declarative Configuration and Meta Configuration.
Declarative Configuration¶
The Declarative Configuration approach is modeled after the SQLAlchemy Declarative ORM itself. It allows you to configure a model attribute’s serialization and de-serialization when defining the model attribute.
Here’s a super-simplified example of how it works:
from sqlathanor import declarative_base, Column, relationship
from sqlalchemy import Integer, String
BaseModel = declarative_base()
class User(BaseModel):
__tablename__ = 'users'
id = Column('id',
Integer,
primary_key = True,
supports_csv = True,
csv_sequence = 1,
supports_json = True,
supports_yaml = True,
supports_dict = True,
on_serialize = None,
on_deserialize = None,
display_name = None)
This example defines a model class called User which corresponds
to a SQL database table named users. The User class defines one
model attribute named id (which corresponds to a
database Column named id). The database
column is an integer, and it operates as the primary key for the database table.
So far, this is all exactly like you would normally see in the SQLAlchemy Declarative ORM.
But, there are some additional arguments supplied to
Column: supports_csv, csv_sequence,
supports_json, supports_yaml, supports_dict, on_serialize, and
on_deserialize. As you can probably guess, these arguments are what configure
serialization and de-serialization in SQLAthanor when using
declarative configuration.
Here’s what these arguments do:
-
SQLAthanor Configuration Arguments Parameters: - supports_csv (
boolortupleof form (inbound:bool, outbound:bool)) –Determines whether the column can be serialized to or de-serialized from CSV format.
If
True, can be serialized to CSV and de-serialized from CSV. IfFalse, will not be included when serialized to CSV and will be ignored if present in a de-serialized CSV.Can also accept a 2-member
tuple(inbound / outbound) which determines de-serialization and serialization support respectively.Defaults to
False, which means the column will not be serialized to CSV or de-serialized from CSV. - csv_sequence (
intorNone) –Indicates the numbered position that the column should be in in a valid CSV-version of the object. Defaults to
None.Note
If not specified, the column will go after any columns that do have a
csv_sequenceassigned, sorted alphabetically.If two columns have the same
csv_sequence, they will be sorted alphabetically. - supports_json (
boolortupleof form (inbound:bool, outbound:bool)) –Determines whether the column can be serialized to or de-serialized from JSON format.
If
True, can be serialized to JSON and de-serialized from JSON. IfFalse, will not be included when serialized to JSON and will be ignored if present in a de-serialized JSON.Can also accept a 2-member
tuple(inbound / outbound) which determines de-serialization and serialization support respectively.Defaults to
False, which means the column will not be serialized to JSON or de-serialized from JSON. - supports_yaml (
boolortupleof form (inbound:bool, outbound:bool)) –Determines whether the column can be serialized to or de-serialized from YAML format.
If
True, can be serialized to YAML and de-serialized from YAML. IfFalse, will not be included when serialized to YAML and will be ignored if present in a de-serialized YAML.Can also accept a 2-member
tuple(inbound / outbound) which determines de-serialization and serialization support respectively.Defaults to
False, which means the column will not be serialized to YAML or de-serialized from YAML. - supports_dict (
boolortupleof form (inbound:bool, outbound:bool)) –Determines whether the column can be serialized to or de-serialized from a Python
dict.If
True, can be serialized todictand de-serialized from adict. IfFalse, will not be included when serialized todictand will be ignored if present in a de-serializeddict.Can also accept a 2-member
tuple(inbound / outbound) which determines de-serialization and serialization support respectively.Defaults to
False, which means the column will not be serialized to adictor de-serialized from adict. - on_deserialize (callable or
dictwith formats as keys and values as callables) –A function that will be called when attempting to assign a de-serialized value to the column. This is intended to either coerce the value being assigned to a form that is acceptable by the column, or raise an exception if it cannot be coerced. If
None, the data type’s defaulton_deserializefunction will be called instead.Tip
If you need to execute different
on_deserializefunctions for different formats, you can also supply adict:on_deserialize = { 'csv': csv_on_deserialize_callable, 'json': json_on_deserialize_callable, 'yaml': yaml_on_deserialize_callable, 'dict': dict_on_deserialize_callable }
Defaults to
None. - on_serialize (callable or
dictwith formats as keys and values as callables) –A function that will be called when attempting to serialize a value from the column. If
None, the data type’s defaulton_serializefunction will be called instead.Tip
If you need to execute different
on_serializefunctions for different formats, you can also supply adict:on_serialize = { 'csv': csv_on_serialize_callable, 'json': json_on_serialize_callable, 'yaml': yaml_on_serialize_callable, 'dict': dict_on_serialize_callable }
Defaults to
None. - display_name (
str/None) – If notNone, astrthat will replace your model attribute’s name in your serialized object (or where your model attribute’s name will be sought when de-serializing). Defaults toNone
- supports_csv (
When using Declarative Configuration, the exact same arguments can be applied
when defining a relationship using
relationship() as shown in the expanded
example below. Let’s look at a somewhat more complicated example:
from sqlathanor import declarative_base, Column, relationship
from sqlalchemy import Integer, String
BaseModel = declarative_base()
class User(BaseModel):
__tablename__ = 'users'
id = Column('id',
Integer,
primary_key = True,
supports_csv = True,
csv_sequence = 1,
supports_json = True,
supports_yaml = True,
supports_dict = True,
on_serialize = None,
on_deserialize = None,
display_name = None)
addresses = relationship('Address',
backref = 'user',
supports_json = True,
supports_yaml = (True, True),
supports_dict = (True, False),
on_serialize = None,
on_deserialize = None,
display_name = None)
This example is (obviously) very similar to the previous one. But now we have
added a relationship defined using the SQLAthanor
relationship() function. This operates
exactly as the built-in sqlalchemy.relationship()
function. But it has the same set of declarative SQLAthanor configuration attributes.
So in this example, we define a relationship to a different model class
called Address, and assign that relationship to the model attribute
User.addresses. Given the configuration above, the User model will:
- support serializing the
idattribute to CSV, JSON, YAML, anddict- support de-serializing the
idattribute from CSV, JSON, YAML, anddict- support serializing related
addressesto JSON and YAML, but will not include theaddressesattribute when serializing to CSV ordict- support de-serializing related
addressesfrom JSON, YAML, anddict, but not from CSV.
Meta Configuration¶
The Meta Configuration approach is more robust than the Declarative approach. That’s because it supports:
- More model attribute types, including
hybrid properties,
association proxies, and Python
@propertyinstance attributes - The definition of multiple named configuration sets for different serialization and de-serialization rules.
The Meta Configuration approach relies on a special model attribute that
you define for your model class: __serialization__. This attribute
contains one or more lists of
AttributeConfiguration objects,
which are used to indicate the explicit serialization/de-serialization
configuration for your model attributes.
Here’s how you would configure an example User model using the Meta Configuration
approach:
from sqlathanor import declarative_base, Column, relationship, AttributeConfiguration
from sqlalchemy import Integer, String
BaseModel = declarative_base()
class User(BaseModel):
__tablename__ = 'users'
__serialization__ = [AttributeConfiguration(name = 'id',
supports_csv = True,
csv_sequence = 1,
supports_json = True,
supports_yaml = True,
supports_dict = True,
on_serialize = None,
on_deserialize = None),
AttributeConfiguration(name = 'addresses',
supports_json = True,
supports_yaml = (True, True),
supports_dict = (True, False),
on_serialize = None,
on_deserialize = None)]
id = Column('id',
Integer,
primary_key = True)
addresses = relationship('Address',
backref = 'user')
The __serialization__ attribute contains an explicit configuration for both
the id and addresses column. Each
AttributeConfiguration object
supports the same configuration arguments as are used by the
declarative approach, with one addition: It needs
a name argument that explicitly indicates the name of the model attribute
that is being configured.
from sqlathanor import declarative_base, Column, relationship, AttributeConfiguration
from sqlalchemy import Integer, String
BaseModel = declarative_base()
class User(BaseModel):
__tablename__ = 'users'
__serialization__ = {
'with-addresses': [AttributeConfiguration(name = 'id',
supports_csv = True,
csv_sequence = 1,
supports_json = True,
supports_yaml = True,
supports_dict = True,
on_serialize = None,
on_deserialize = None,
display_name = None),
AttributeConfiguration(name = 'addresses',
supports_json = True,
supports_yaml = (True, True),
supports_dict = (True, False),
on_serialize = None,
on_deserialize = None,
display_name = None)],
'without-addresses': [AttributeConfiguration(name = 'id',
supports_csv = True,
csv_sequence = 1,
supports_json = True,
supports_yaml = True,
supports_dict = True,
on_serialize = None,
on_deserialize = None,
display_name = None)],
'different-display-name': [AttributeConfiguration(name = 'id',
supports_csv = True,
csv_sequence = 1,
supports_json = True,
supports_yaml = True,
supports_dict = True,
on_serialize = None,
on_deserialize = None,
display_name = None),
AttributeConfiguration(name = 'addresses',
supports_json = True,
supports_yaml = (True, True),
supports_dict = (True, False),
on_serialize = None,
on_deserialize = None,
display_name = 'custom_address_label')]
}
id = Column('id',
Integer,
primary_key = True)
addresses = relationship('Address',
backref = 'user')
If you will be using different configuration sets, then the __serialization__
attribute contains a dict where each key is the unique name of
a given configuration set and its value is a list of
AttributeConfiguration objects.
In the example provided above, we have created three different named configuration sets:
'with-addresses'which serializes both theidandaddressesattributes,'without-addresses'which serializes just theidattribute but not theaddressesattribute'different-display-name'which serializes both theidandaddressesattribute, but applies a differentdisplay_namewhen serializing theaddressesattribute.
Note
The __serialization__ attribute and its configuration sets accept both
AttributeConfiguration
instances, as well as dict representations of those instances.
If you supply dict configurations, SQLAthanor will
automatically convert them to
AttributeConfiguration
instances.
The __serialization__ below is identical to the one above:
__serialization__ = [
{
'name': 'id',
'supports_csv': True,
'csv_sequence': 1,
'supports_json': True,
'supports_yaml': True,
'supports_dict': True,
'on_serialize': None,
'on_deserialize': None
},
{
'name': 'addresses',
'supports_json': True,
'supports_yaml': (True, True),
'supports_dict': (True, False),
'on_serialize': None,
'on_deserialize': None
}
]
Unlike the declarative approach, you can
use the __serialization__ attribute to configure serialization and de-serialization
for more complex types of model attributes, including
hybrid properties,
association proxies, and Python
@property attributes.
Using the meta configuration approach, you configure these more complex attributes in exactly the same way:
from sqlathanor import declarative_base, Column, relationship, AttributeConfiguration
from sqlalchemy import Integer, String
from sqlalchemy.ext.hybrid import hybrid_property
from sqlalchemy.ext.associationproxy import association_proxy
BaseModel = declarative_base()
class User(BaseModel):
__tablename__ = 'users'
__serialization__ = [AttributeConfiguration(name = 'id',
supports_csv = True,
csv_sequence = 1,
supports_json = True,
supports_yaml = True,
supports_dict = True,
on_serialize = None,
on_deserialize = None),
AttributeConfiguration(name = 'addresses',
supports_json = True,
supports_yaml = (True, True),
supports_dict = (True, False),
on_serialize = None,
on_deserialize = None),
AttributeConfiguration(name = 'hybrid',
supports_csv = True,
csv_sequence = 2,
supports_json = True,
supports_yaml = True,
supports_dict = True,
on_serialize = None,
on_deserialize = None)]
AttributeConfiguration(name = 'keywords',
supports_csv = False,
supports_json = True,
supports_yaml = True,
supports_dict = True,
on_serialize = None,
on_deserialize = None)]
AttributeConfiguration(name = 'python_property',
supports_csv = (False, True),
csv_sequence = 3,
supports_json = (False, True),
supports_yaml = (False, True),
supports_dict = (False, True),
on_serialize = None,
on_deserialize = None)]
id = Column('id',
Integer,
primary_key = True)
addresses = relationship('Address',
backref = 'user')
_hybrid = 1
@hybrid_property
def hybrid(self):
return self._hybrid
@hybrid.setter
def hybrid(self, value):
self._hybrid = value
@hybrid.expression
def hybrid(cls):
return False
keywords = association_proxy('keywords', 'keyword')
@property
def python_property(self):
return self._hybrid * 2
This more complicated pattern extends the earlier example with a
hybrid property nammed hybrid, an association proxy named
keywords, and an instance attribute (defined using
@property) named python_property.
- The
__serialization__configuration shown ensures that: hybridcan be serialized to and de-serialized from CSV, JSON, YAML, anddict.keywordscan be serialized to and de-serialized from JSON, YAML, anddict, but cannot be serialized to or de-serialized from CSV.python_propertycan be serialized to all formats, but cannot be de-serialized (which makes sense, since it is defined without asetter)
Warning
A configuration found in __serialization__ always takes precedence.
This means that if you mix the declarative and
meta approaches, the configuration in
__serialization__ will be applied.
Tip
For security reasons, if you don’t explicitly configure serialization/de-serialization for a model attribute using the meta or declarative approach, by default that attribute will not be serialized and will be ignored when de-serializing.
Meta Configuration vs Declarative Configuration¶
How should you choose between the meta configuration and declarative configuration approach?
Well, to some extent it’s a question of personal preference. For example, I always use the meta approach because I believe it is cleaner, easier to maintain, and more extensible. But as you can probably tell if you look at my code, I tend to be a bit pedantic about such things. There are plenty of times when the declarative approach will make sense and “feel” right.
Here’s a handy flowchart to help you figure out which you should use:
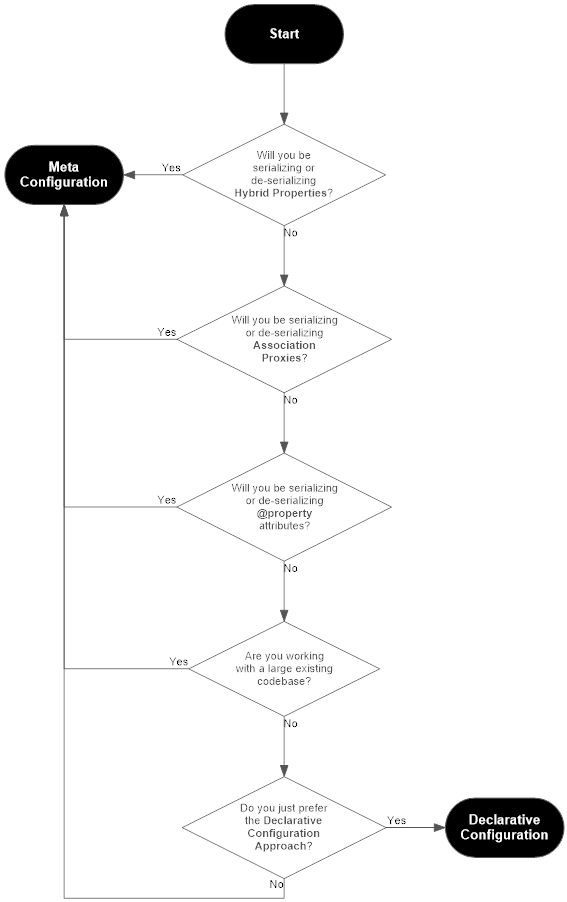
Why Two Configuration Approaches?¶
The Zen of Python holds that:
There should be one– and preferably only one –obvious way to do it.And that is a very wise principle. But there are times when it makes sense to diverge from that principle. I made a conscious choice to support two different configuration mechanisms for several practical reasons:
- SQLAlchemy has been around for a long time, and is very popular. There are many existing codebases that might benefit from integrating with SQLAthanor. The meta configuration approach lets users make minimal changes to their existing codebases at minimal risk.
- SQLAlchemy is often used in quick-and-dirty projects where the additional overhead of defining an explicit meta configuration in the
__serialization__class attribute will interrupt a programmer’s “flow”. The SQLAlchemy Declarative ORM already provides a great API for defining a model with minimal overhead, so piggybacking on that familiar API will enhance the programmer experience.- The internal mechanics of how SQLAlchemy implements hybrid properties and association proxies are very complicated, and can be mutated at various points in a model class or model instance lifecycle. As a result, supporting them in the declarative configuration approach would have been very complicated, with a lot of exposure to potential edge case errors. But the meta configuration approach neatly avoids those risks.
- The only way for the declarative configuration approach to support serialization and de-serialization of model attributes defined using Python’s built-in
@propertydecorator would require extending a feature of the standard library…which I consider an anti-pattern that should be done rarely (if ever).So given those arguments, you might ask: Why not just use the meta configuration approach, and call it a day? It clearly has major advantages. And yes, you’d be right to ask the question. It does have major advantages, and it is the one I use almost-exclusively in my own code.
But!
I’ve spent close to twenty years in the world of data science and analytics, and I know what the coding practices in that community look like and how SQLAlchemy often gets used “in the wild”. And that experience and knowledge tells me that the declarative approach will just “feel more natural” to a large number of data scientists and developers who have a particular workflow, particular coding style, specific coding conventions, and who often don’t need SQLAlchemy’s more complicated features like hybrid properties or association proxies.
And since SQLAthanor can provide benefits to both “application developers” and “data scientists”, I’ve tried to design an interface that will feel “natural” to both communities.
Configuring at Runtime¶
See also
SQLAthanor exposes a number of public methods that allow you to modify the serialization/de-serialization configuration at run-time. For more information, please see:
5. Configuring Pre-processing and Post-processing¶
When serializing and de-serializing objects, it is often necessary to either convert data to a more-compatible format, or to validate inbound data to ensure it meets your expectations.
SQLAthanor supports this using serialization pre-processing and de-serialization
post-processing, as configured in the on_serialize and on_deserialize
configuration arguments.
Serialization Pre-processing¶
The on_deserialize configuration argument
allows you to assign a serialization function to a particular
model attribute.
If assigned, the serialization function will be called before the model attribute’s value gets serialized into its target format. This is particularly useful when you need to convert a value from its native (in Python) type/format into a type/format that is supported by the serialized data type.
A typical example of this might be converting a None
value in Python to an empty string '' that can be included in a
CSV record, or ensuring a decimal value
is appropriately rounded.
The on_serialize argument expects to receive
either a callable (a Python function), or a dict where
keys correspond to SQLAthanor’s supported formats and values are the callables
to use for that format. Thus:
...
on_serialize = my_serialization_function,
...
will call the my_serialization_function() whenever serializing the value, but
...
on_serialize = {
'csv': my_csv_serialization_function,
'json': my_json_serialization_function,
'yaml': my_yaml_serialization_function,
'dict': my_dict_serialization_function
},
...
will call a different function when serializing the value to each of the four formats given above.
Tip
If on_serialize is None, or if its value for a particular
format is None, then SQLAthanor will default to a
Default Serialization Function based on the
data type of the model attribute.
If defining your own custom serializer function, please bear in mind that a valid serializer function will:
- accept one positional argument, which is the value of the model attribute to be serialized, and
- return one value, which is the value that will be included in the serialized output.
De-serialization Post-processing¶
The on_deserialize configuration argument
allows you to assign a de-serialization function to a particular
model attribute.
If assigned, the de-serialization function will be called after your serialized object is parsed, but before the value is assigned to your Python model attribute. This is particularly useful when you need to:
- convert a value from its serialized format (e.g. a string) into the type supported by your model class (e.g. an integer),
- validate that a serialized value is “correct” (matches your expectations),
- do something to the value before persisting it (e.g. hash and salt) to the database.
A typical example of this might be:
- converting an empty string
''in a CSV record intoNone - validating that the serialized value is a proper telephone number
- hashing an inbound password.
The on_deserialize argument expects to receive
either a callable (a Python function), or a dict where
keys correspond to SQLAthanor’s supported formats and values are the callables
to use for that format. Thus:
...
on_deserialize = my_deserialization_function,
...
will call the my_deserialization_function() whenever de-serializing the value,
but
...
on_deserialize = {
'csv': my_csv_deserialization_function,
'json': my_json_deserialization_function,
'yaml': my_yaml_deserialization_function,
'dict': my_dict_deserialization_function
},
...
will call a different function when de-serializing the value to each of the four formats given above.
Tip
If on_deserialize is None, or if its value for a particular
format is None, then SQLAthanor will default to a
Default De-serialization Function based on the
data type of the model attribute being de-serialized.
If defining your own custom deserializer function, please bear in mind that a valid deserializer function will:
- accept one positional argument, which is the value for the model attribute as found in the serialized input, and
- return one value, which is the value that will be assigned to the model attribute (and thus probably persisted to the underlying database).
See also
6. Serializing a Model Instance¶
Once you’ve configured your model class, you can
now easily serialize it. Your model instance will have two serialization
methods for each of the formats, named to_<format> and dump_to_<format>
respectively, where <format> corresponds to csv, json, yaml, and
dict:
The to_<format> methods adhere to whatever configuration
you have set up for your model class, while the dump_to_<format> method will
automatically serialize all model attributes defined.
Caution
Use the the dump_to_<format> methods with caution!
Because they automatically serialize all model attributes defined for your model class, they potentially expose your application to security vulnerabilities.
Nesting Complex Data¶
SQLAthanor automatically supports nesting complex structures in JSON, YAML,
and dict. However, to prevent the risk of infinite recursion,
those formats serialization methods all feature a required max_nesting argument.
By default, it is set to 0 which prevents model attributes
that resolve to another model class from being included in a serialized output.
Unlike other supported formats, CSV works
best with “flat” structures where each output column contains one and only one
simple value, and so to_csv() does not include any max_nesting or
current_nesting arguments.
Tip
As a general rule of thumb, we recommend that you avoid enabling CSV serialization on relationships unless using a custom serialization function to structure nested data.
to_csv()¶
-
BaseModel.to_csv(include_header=False, delimiter='|', wrap_all_strings=False, null_text='None', wrapper_character="'", double_wrapper_character_when_nested=False, escape_character='\\', line_terminator='\r\n', config_set=None)¶ Retrieve a CSV string with the object’s data.
Parameters: - include_header (
bool) – IfTrue, will include a header row with column labels. IfFalse, will not include a header row. Defaults toTrue. - delimiter (
str) – The delimiter used between columns. Defaults to|. - wrap_all_strings (
bool) – IfTrue, wraps any string data in thewrapper_character. IfNone, only wraps string data if it contains thedelimiter. Defaults toFalse. - null_text (
str) – The text value to use in place of empty values. Only applies ifwrap_empty_valuesisTrue. Defaults to'None'. - wrapper_character (
str) – The string used to wrap string values when wrapping is necessary. Defaults to'. - double_wrapper_character_when_nested (
bool) – IfTrue, will double thewrapper_characterwhen it is found inside a column value. IfFalse, will precede thewrapper_characterby theescape_characterwhen it is found inside a column value. Defaults toFalse. - escape_character (
str) – The character to use when escaping nested wrapper characters. Defaults to\. - line_terminator (
str) – The character used to mark the end of a line. Defaults to\r\n. - config_set (
str/None) – If notNone, the named configuration set to use. Defaults toNone.
Returns: Data from the object in CSV format ending in a newline (
\n).Return type: - include_header (
to_json()¶
-
BaseModel.to_json(max_nesting=0, current_nesting=0, serialize_function=None, config_set=None, **kwargs)¶ Return a JSON representation of the object.
Parameters: - max_nesting (
int) – The maximum number of levels that the resulting JSON object can be nested. If set to0, will not nest other serializable objects. Defaults to0. - current_nesting (
int) – The current nesting level at which thedictrepresentation will reside. Defaults to0. - serialize_function (callable /
None) –Optionally override the default JSON serializer. Defaults to
None, which applies the default simplejson JSON serializer.Note
Use the
serialize_functionparameter to override the default JSON serializer.A valid
serialize_functionis expected to accept a singledictand return astr, similar tosimplejson.dumps().If you wish to pass additional arguments to your
serialize_functionpass them as keyword arguments (inkwargs). - config_set (
str/None) – If notNone, the named configuration set to use. Defaults toNone. - kwargs (keyword arguments) – Optional keyword parameters that are passed to the
JSON serializer function. By default, these are options which are passed
to
simplejson.dumps().
Returns: A
strwith the JSON representation of the object.Return type: Raises: - SerializableAttributeError – if attributes is empty
- MaximumNestingExceededError – if
current_nestingis greater thanmax_nesting - MaximumNestingExceededWarning – if an attribute requires nesting
beyond
max_nesting
- max_nesting (
to_yaml()¶
-
BaseModel.to_yaml(max_nesting=0, current_nesting=0, serialize_function=None, config_set=None, **kwargs)¶ Return a YAML representation of the object.
Parameters: - max_nesting (
int) – The maximum number of levels that the resulting object can be nested. If set to0, will not nest other serializable objects. Defaults to0. - current_nesting (
int) – The current nesting level at which the representation will reside. Defaults to0. - serialize_function (callable /
None) –Optionally override the default YAML serializer. Defaults to
None, which calls the defaultyaml.dump()function from the PyYAML library. - config_set (
str/None) – If notNone, the named configuration set to use. Defaults toNone. - kwargs (keyword arguments) – Optional keyword parameters that are passed to the
YAML serializer function. By default, these are options which are passed
to
yaml.dump().
Returns: A
strwith the JSON representation of the object.Return type: Raises: - SerializableAttributeError – if attributes is empty
- MaximumNestingExceededError – if
current_nestingis greater thanmax_nesting - MaximumNestingExceededWarning – if an attribute requires nesting
beyond
max_nesting
- max_nesting (
to_dict()¶
-
BaseModel.to_dict(max_nesting=0, current_nesting=0, config_set=None)¶ Return a
OrderedDictrepresentation of the object.Parameters: - max_nesting (
int) – The maximum number of levels that the resultingdictobject can be nested. If set to0, will not nest other serializable objects. Defaults to0. - current_nesting (
int) – The current nesting level at which thedictrepresentation will reside. Defaults to0. - config_set (
str/None) – If notNone, the named configuration set to use when processing the input. Defaults toNone.
Returns: A
OrderedDictrepresentation of the object.Return type: Raises: - SerializableAttributeError – if attributes is empty
- MaximumNestingExceededError – if
current_nestingis greater thanmax_nesting - MaximumNestingExceededWarning – if an attribute requires nesting
beyond
max_nesting
- max_nesting (
dump_to_csv()¶
-
BaseModel.dump_to_csv(include_header=False, delimiter='|', wrap_all_strings=False, null_text='None', wrapper_character="'", double_wrapper_character_when_nested=False, escape_character='\\', line_terminator='\r\n', config_set=None)¶ Retrieve a CSV representation of the object, with all attributes serialized regardless of configuration.
Caution
Nested objects (such as relationships or association proxies) will not be serialized.
Note
This method ignores any
display_namecontributed on theAttributeConfiguration.Parameters: - include_header (
bool) – IfTrue, will include a header row with column labels. IfFalse, will not include a header row. Defaults toTrue. - delimiter (
str) – The delimiter used between columns. Defaults to|. - wrap_all_strings (
bool) – IfTrue, wraps any string data in thewrapper_character. IfNone, only wraps string data if it contains thedelimiter. Defaults toFalse. - null_text (
str) – The text value to use in place of empty values. Only applies ifwrap_empty_valuesisTrue. Defaults to'None'. - wrapper_character (
str) – The string used to wrap string values when wrapping is necessary. Defaults to'. - double_wrapper_character_when_nested (
bool) – IfTrue, will double thewrapper_characterwhen it is found inside a column value. IfFalse, will precede thewrapper_characterby theescape_characterwhen it is found inside a column value. Defaults toFalse. - escape_character (
str) – The character to use when escaping nested wrapper characters. Defaults to\. - line_terminator (
str) – The character used to mark the end of a line. Defaults to\r\n. - config_set (
str/None) – If notNone, the named configuration set to use. Defaults toNone.
Returns: Data from the object in CSV format ending in a newline (
\n).Return type: - include_header (
dump_to_json()¶
-
BaseModel.dump_to_json(max_nesting=0, current_nesting=0, serialize_function=None, config_set=None, **kwargs)¶ Return a JSON representation of the object, with all attributes regardless of configuration.
Caution
Nested objects (such as relationships or association proxies) will not be serialized.
Parameters: - max_nesting (
int) – The maximum number of levels that the resulting JSON object can be nested. If set to0, will not nest other serializable objects. Defaults to0. - current_nesting (
int) – The current nesting level at which thedictrepresentation will reside. Defaults to0. - serialize_function (callable /
None) –Optionally override the default JSON serializer. Defaults to
None, which applies the default simplejson JSON serializer.Note
Use the
serialize_functionparameter to override the default JSON serializer.A valid
serialize_functionis expected to accept a singledictand return astr, similar tosimplejson.dumps().If you wish to pass additional arguments to your
serialize_functionpass them as keyword arguments (inkwargs). - config_set (
str/None) – If notNone, the named configuration set to use. Defaults toNone. - kwargs (keyword arguments) – Optional keyword parameters that are passed to the
JSON serializer function. By default, these are options which are passed
to
simplejson.dumps().
Returns: A
strwith the JSON representation of the object.Return type: Raises: - SerializableAttributeError – if attributes is empty
- MaximumNestingExceededError – if
current_nestingis greater thanmax_nesting - MaximumNestingExceededWarning – if an attribute requires nesting
beyond
max_nesting
- max_nesting (
dump_to_yaml()¶
-
BaseModel.dump_to_yaml(max_nesting=0, current_nesting=0, serialize_function=None, config_set=None, **kwargs)¶ Return a YAML representation of the object with all attributes, regardless of configuration.
Caution
Nested objects (such as relationships or association proxies) will not be serialized.
Parameters: - max_nesting (
int) – The maximum number of levels that the resulting object can be nested. If set to0, will not nest other serializable objects. Defaults to0. - current_nesting (
int) – The current nesting level at which the representation will reside. Defaults to0. - serialize_function (callable /
None) –Optionally override the default YAML serializer. Defaults to
None, which calls the defaultyaml.dump()function from the PyYAML library. - config_set (
str/None) – If notNone, the named configuration set to use. Defaults toNone. - kwargs (keyword arguments) – Optional keyword parameters that are passed to the
YAML serializer function. By default, these are options which are passed
to
yaml.dump().
Returns: A
strwith the JSON representation of the object.Return type: Raises: - SerializableAttributeError – if attributes is empty
- MaximumNestingExceededError – if
current_nestingis greater thanmax_nesting - MaximumNestingExceededWarning – if an attribute requires nesting
beyond
max_nesting
- max_nesting (
dump_to_dict()¶
-
BaseModel.dump_to_dict(max_nesting=0, current_nesting=0, config_set=None)¶ Return a
OrderedDictrepresentation of the object, with all attributes regardless of configuration.Caution
Nested objects (such as relationships or association proxies) will not be serialized.
Parameters: - max_nesting (
int) – The maximum number of levels that the resultingOrderedDictobject can be nested. If set to0, will not nest other serializable objects. Defaults to0. - current_nesting (
int) – The current nesting level at which thedictrepresentation will reside. Defaults to0. - config_set (
str/None) – If notNone, the named configuration set to use when processing the input. Defaults toNone.
Returns: A
OrderedDictrepresentation of the object.Return type: Raises: - SerializableAttributeError – if attributes is empty
- MaximumNestingExceededError – if
current_nestingis greater thanmax_nesting - MaximumNestingExceededWarning – if an attribute requires nesting
beyond
max_nesting
- max_nesting (
7. Deserializing Data¶
Once you’ve configured your model class, you can now easily de-serialize it from the formats you have enabled.
However, unlike serializing your data, there are actually two types of de-serialization method to choose from:
- The
new_from_<format>method operates on your model class directly and create a new model instance whose properties are set based on the data you are de-serializing. - The
update_from_<format>methods operate on a model instance, and update that instance’s properties based on the data you are de-serializing.
Creating New:
Updating:
Creating New Instances¶
new_from_csv()¶
-
classmethod
BaseModel.new_from_csv(csv_data, delimiter='|', wrap_all_strings=False, null_text='None', wrapper_character="'", double_wrapper_character_when_nested=False, escape_character='\\', line_terminator='\r\n', config_set=None)¶ Create a new model instance from a CSV record.
Tip
Unwrapped empty column values are automatically interpreted as null (
None).Parameters: - csv_data (
str/ Path-like object) – The CSV data. If a Path-like object, will read the first record from a file that is assumed to include a header row. If astrand has more than one record (line), will assume the first line is a header row. - delimiter (
str) – The delimiter used between columns. Defaults to|. - wrapper_character (
str) – The string used to wrap string values when wrapping is applied. Defaults to'. - null_text (
str) – The string used to indicate an empty value if empty values are wrapped. Defaults to None. - config_set (
str/None) – If notNone, the named configuration set to use. Defaults toNone.
Returns: A model instance created from the record.
Return type: model instance
Raises: - DeserializationError – if
csv_datais not a validstr - CSVStructureError – if the columns in
csv_datado not match the expected columns returned byget_csv_column_names() - ValueDeserializationError – if a value extracted from the CSV failed when executing its de-serialization function.
- csv_data (
new_from_json()¶
-
classmethod
BaseModel.new_from_json(input_data, deserialize_function=None, error_on_extra_keys=True, drop_extra_keys=False, config_set=None, **kwargs)¶ Create a new model instance from data in JSON.
Parameters: - input_data (
stror Path-like object) –The JSON data to de-serialize.
Note
If
input_datapoints to a file, and the file contains a list of JSON objects, the first JSON object will be considered. - deserialize_function (callable /
None) –Optionally override the default JSON deserializer. Defaults to
None, which calls the defaultsimplejson.loads()function from the doc:simplejson <simplejson:index> library.Note
Use the
deserialize_functionparameter to override the default JSON deserializer.A valid
deserialize_functionis expected to accept a singlestrand return adict, similar tosimplejson.loads().If you wish to pass additional arguments to your
deserialize_functionpass them as keyword arguments (inkwargs). - error_on_extra_keys (
bool) –If
True, will raise an error if an unrecognized key is found ininput_data. IfFalse, will either drop or include the extra key in the result, as configured in thedrop_extra_keysparameter. Defaults toTrue.Warning
Be careful setting
error_on_extra_keystoFalse.This method’s last step passes the keys/values of the processed input data to your model’s
__init__()method.If your instance’s
__init__()method does not support your extra keys, it will likely raise aTypeError. - drop_extra_keys (
bool) – IfTrue, will ignore unrecognized top-level keys ininput_data. IfFalse, will include unrecognized keys or raise an error based on the configuration of theerror_on_extra_keysparameter. Defaults toFalse. - config_set (
str/None) – If notNone, the named configuration set to use. Defaults toNone. - kwargs (keyword arguments) – Optional keyword parameters that are passed to the
JSON deserializer function. By default, these are options which are passed
to
simplejson.loads().
Raises: - ExtraKeyError – if
error_on_extra_keysisTrueandinput_datacontains top-level keys that are not recognized as attributes for the instance model. - DeserializationError – if
input_datais not adictor JSON object serializable to adictor ifinput_datais empty.
- input_data (
new_from_yaml()¶
-
classmethod
BaseModel.new_from_yaml(input_data, deserialize_function=None, error_on_extra_keys=True, drop_extra_keys=False, config_set=None, **kwargs)¶ Create a new model instance from data in YAML.
Parameters: - input_data (
str/ Path-like object) – The YAML data to de-serialize. May be either astror a Path-like object to a YAML file. - deserialize_function (callable /
None) –Optionally override the default YAML deserializer. Defaults to
None, which calls the defaultyaml.safe_load()function from the PyYAML library.Note
Use the
deserialize_functionparameter to override the default YAML deserializer.A valid
deserialize_functionis expected to accept a singlestrand return adict, similar toyaml.safe_load().If you wish to pass additional arguments to your
deserialize_functionpass them as keyword arguments (inkwargs). - error_on_extra_keys (
bool) –If
True, will raise an error if an unrecognized key is found ininput_data. IfFalse, will either drop or include the extra key in the result, as configured in thedrop_extra_keysparameter. Defaults toTrue.Warning
Be careful setting
error_on_extra_keystoFalse.This method’s last step passes the keys/values of the processed input data to your model’s
__init__()method.If your instance’s
__init__()method does not support your extra keys, it will likely raise aTypeError. - drop_extra_keys (
bool) – IfTrue, will ignore unrecognized top-level keys ininput_data. IfFalse, will include unrecognized keys or raise an error based on the configuration of theerror_on_extra_keysparameter. Defaults toFalse. - config_set (
str/None) – If notNone, the named configuration set to use. Defaults toNone.
Raises: - ExtraKeyError – if
error_on_extra_keysisTrueandinput_datacontains top-level keys that are not recognized as attributes for the instance model. - DeserializationError – if
input_datais not adictor JSON object serializable to adictor ifinput_datais empty.
- input_data (
new_from_dict()¶
-
classmethod
BaseModel.new_from_dict(input_data, error_on_extra_keys=True, drop_extra_keys=False, config_set=None)¶ Update the model instance from data in a
dictobject.Parameters: - input_data (
dict) – The inputdict - error_on_extra_keys (
bool) –If
True, will raise an error if an unrecognized key is found ininput_data. IfFalse, will either drop or include the extra key in the result, as configured in thedrop_extra_keysparameter. Defaults toTrue.Warning
Be careful setting
error_on_extra_keystoFalse.This method’s last step passes the keys/values of the processed input data to your model’s
__init__()method.If your instance’s
__init__()method does not support your extra keys, it will likely raise aTypeError. - drop_extra_keys (
bool) – IfTrue, will omit unrecognized top-level keys from the resultingdict. IfFalse, will include unrecognized keys or raise an error based on the configuration of theerror_on_extra_keysparameter. Defaults toFalse. - config_set (
str/None) – If notNone, the named configuration set to use when processing the input. Defaults toNone.
Raises: - ExtraKeyError – if
error_on_extra_keysisTrueandinput_datacontains top-level keys that are not recognized as attributes for the instance model. - DeserializationError – if
input_datais not adictor JSON object serializable to adictor ifinput_datais empty.
- input_data (
Updating Instances¶
update_from_csv()¶
-
BaseModel.update_from_csv(csv_data, delimiter='|', wrap_all_strings=False, null_text='None', wrapper_character="'", double_wrapper_character_when_nested=False, escape_character='\\', line_terminator='\r\n', config_set=None)¶ Update the model instance from a CSV record.
Tip
Unwrapped empty column values are automatically interpreted as null (
None).Parameters: - csv_data (
str/ Path-like object) – The CSV data. If a Path-like object, will read the first record from a file that is assumed to include a header row. If astrand has more than one record (line), will assume the first line is a header row. - delimiter (
str) – The delimiter used between columns. Defaults to|. - wrapper_character (
str) – The string used to wrap string values when wrapping is applied. Defaults to'. - null_text (
str) – The string used to indicate an empty value if empty values are wrapped. Defaults to None. - config_set (
str/None) – If notNone, the named configuration set to use. Defaults toNone.
Raises: - DeserializationError – if
csv_datais not a validstr - CSVStructureError – if the columns in
csv_datado not match the expected columns returned byget_csv_column_names() - ValueDeserializationError – if a value extracted from the CSV failed when executing its de-serialization function.
- csv_data (
update_from_json()¶
-
BaseModel.update_from_json(input_data, deserialize_function=None, error_on_extra_keys=True, drop_extra_keys=False, config_set=None, **kwargs)¶ Update the model instance from data in a JSON string.
Parameters: - input_data (
stror Path-like object) –The JSON data to de-serialize.
Note
If
input_datapoints to a file, and the file contains a list of JSON objects, the first JSON object will be considered. - deserialize_function (callable /
None) –Optionally override the default JSON deserializer. Defaults to
None, which calls the defaultsimplejson.loads()function from the simplejson library.Note
Use the
deserialize_functionparameter to override the default JSON deserializer.A valid
deserialize_functionis expected to accept a singlestrand return adict, similar tosimplejson.loads().If you wish to pass additional arguments to your
deserialize_functionpass them as keyword arguments (inkwargs). - error_on_extra_keys (
bool) –If
True, will raise an error if an unrecognized key is found ininput_data. IfFalse, will either drop or include the extra key in the result, as configured in thedrop_extra_keysparameter. Defaults toTrue.Warning
Be careful setting
error_on_extra_keystoFalse.This method’s last step attempts to set an attribute on the model instance for every top-level key in the parsed/processed input data.
If there is an extra key that cannot be set as an attribute on your model instance, it will raise
AttributeError. - drop_extra_keys (
bool) – IfTrue, will ignore unrecognized keys in the input data. IfFalse, will include unrecognized keys or raise an error based on the configuration of theerror_on_extra_keysparameter. Defaults toFalse. - config_set (
str/None) – If notNone, the named configuration set to use. Defaults toNone. - kwargs (keyword arguments) – Optional keyword parameters that are passed to the
JSON deserializer function.By default, these are options which are passed
to
simplejson.loads().
Raises: - ExtraKeyError – if
error_on_extra_keysisTrueandinput_datacontains top-level keys that are not recognized as attributes for the instance model. - DeserializationError – if
input_datais not astrJSON de-serializable object to adictor ifinput_datais empty.
- input_data (
update_from_yaml()¶
-
BaseModel.update_from_yaml(input_data, deserialize_function=None, error_on_extra_keys=True, drop_extra_keys=False, config_set=None, **kwargs)¶ Update the model instance from data in a YAML string.
Parameters: - input_data (
str/ Path-like object) – The YAML data to de-serialize. May be either astror a Path-like object to a YAML file. - deserialize_function (callable /
None) –Optionally override the default YAML deserializer. Defaults to
None, which calls the defaultyaml.safe_load()function from the PyYAML library.Note
Use the
deserialize_functionparameter to override the default YAML deserializer.A valid
deserialize_functionis expected to accept a singlestrand return adict, similar toyaml.safe_load().If you wish to pass additional arguments to your
deserialize_functionpass them as keyword arguments (inkwargs). - error_on_extra_keys (
bool) –If
True, will raise an error if an unrecognized key is found ininput_data. IfFalse, will either drop or include the extra key in the result, as configured in thedrop_extra_keysparameter. Defaults toTrue.Warning
Be careful setting
error_on_extra_keystoFalse.This method’s last step attempts to set an attribute on the model instance for every top-level key in the parsed/processed input data.
If there is an extra key that cannot be set as an attribute on your model instance, it will raise
AttributeError. - drop_extra_keys (
bool) – IfTrue, will ignore unrecognized keys in the input data. IfFalse, will include unrecognized keys or raise an error based on the configuration of theerror_on_extra_keysparameter. Defaults toFalse. - config_set (
str/None) – If notNone, the named configuration set to use. Defaults toNone. - kwargs (keyword arguments) – Optional keyword parameters that are passed to the
YAML deserializer function. By default, these are options which are passed
to
yaml.safe_load().
Raises: - ExtraKeyError – if
error_on_extra_keysisTrueandinput_datacontains top-level keys that are not recognized as attributes for the instance model. - DeserializationError – if
input_datais not astrYAML de-serializable object to adictor ifinput_datais empty.
- input_data (
update_from_dict()¶
-
BaseModel.update_from_dict(input_data, error_on_extra_keys=True, drop_extra_keys=False, config_set=None)¶ Update the model instance from data in a
dictobject.Parameters: - input_data (
dict) – The inputdict - error_on_extra_keys (
bool) –If
True, will raise an error if an unrecognized key is found ininput_data. IfFalse, will either drop or include the extra key in the result, as configured in thedrop_extra_keysparameter. Defaults toTrue.Warning
Be careful setting
error_on_extra_keystoFalse.This method’s last step attempts to set an attribute on the model instance for every top-level key in the parsed/processed input data.
If there is an extra key that cannot be set as an attribute on your model instance, it will raise
AttributeError. - drop_extra_keys (
bool) – IfTrue, will omit unrecognized top-level keys from the resultingdict. IfFalse, will include unrecognized keys or raise an error based on the configuration of theerror_on_extra_keysparameter. Defaults toFalse. - config_set (
str/None) – If notNone, the named configuration set to use when processing the input. Defaults toNone.
Raises: - ExtraKeyError – if
error_on_extra_keysisTrueandinput_datacontains top-level keys that are not recognized as attributes for the instance model. - DeserializationError – if
input_datais not adictor JSON object serializable to adictor ifinput_datais empty.
- input_data (
Using Declarative Reflection with SQLAthanor¶
SQLAlchemy supports the use of reflection with the SQLAlchemy Declarative ORM.
This is a process where SQLAlchemy automatically constructs a
Declarative
model class based on what it reads from the table definition stored in your
SQL database or a corresponding Table
instance already defined and registered with a
MetaData object.
See also
- SQLAlchemy: Reflecting Database Objects
- SQLAlchemy: Using Reflection with Declarative
- Using Automap with SQLAthanor
SQLAthanor is also compatible with this pattern. In fact, it works just as you might expect. At a minimum:
from sqlathanor import declarative_base, Column, relationship, AttributeConfiguration
from sqlalchemy import create_engine, Integer, String, Table
from sqlalchemy.ext.hybrid import hybrid_property
from sqlalchemy.ext.associationproxy import association_proxy
engine = create_engine('... ENGINE CONFIGURATION GOES HERE ...')
# NOTE: Because reflection relies on a specific SQLAlchemy Engine existing, presumably
# you would know how to configure / instantiate your database engine using SQLAlchemy.
# This is just here for the sake of completeness.
BaseModel = declarative_base()
class ReflectedUser(BaseModel):
__table__ = Table('users',
BaseModel.metadata,
autoload = True,
autoload_with = engine)
will read the structure of your users table, and populate your ReflectedUser
model class with model attributes that correspond to
the table’s columns as defined in the underlying SQL table.
Caution
By design, SQLAlchemy’s reflection ONLY reflects Column definitions.
It does NOT reflect relationships that you may
otherwise model using SQLAlchemy.
Because the ReflectedUser class inherits from the SQLAthanor base model,
it establishes the __serialization__ attribute, and the
to_csv(),
to_json(),
to_yaml(), and
to_dict() methods on the ReflectedUser
class.
When working with a reflected model class, you can configure serialization/deserialization using either the declarative or meta approach as you normally would.
Warning
In the example above, if the database table named users already has a
Table associated with
it, ReflectedUser will inherit the Column definitions from the
“original” Table object.
If those column definitions are defined using sqlathanor.schema.Column
with declarative, their
serialization/deserialization will also be reflected (inherited).
However, the ReflectedUser model class will NOT inherit any
serialization/deserialization configuration defined using the
meta approach.
Just as with standard SQLAlchemy reflection, you can override your
Column definitions in your reflecting class
(ReflectedUser), or add additional
relationship
model attributes, hybrid properties,
or association proxies to the reflecting class.
Using Automap with SQLAthanor¶
New in version 0.2.0.
Caution
Automap was introduced in
SQLAlchemy v.0.9.1. If you are using SQLAthanor with SQLAlchemy
v.0.9.0, then if you attempt to use
automap_base() you will raise a
SQLAlchemySupportError.
The Automap Extension is an incredibly useful tool for modeling existing databases with minimal effort. What it does is it reasd your existing database’s metadata and automatically constructs SQLAlchemy Declarative ORM model classes populated with your tables’ columns.
Neat, right? Saves a ton of effort.
Using SQLAthanor you can ensure that your automapped (automatically generated) models support serialization and de-serialization.
First, you need to create your automapped classes. This works just like in
Automap, only you import
automap_base() from SQLAthanor
instead as shown below:
from sqlathanor.automap import automap_base
from sqlalchemy import create_engine
# Create your Automap Base
Base = automap_base()
engine = create_engine('... DATABASE CONNECTION GOES HERE ...')
# Prepare your automap base. This reads your database and creates your models.
Base.prepare(engine, reflect = True)
# And here you can create a "User" model class and an "Address" model class.
User = Base.classes.users
Address = Base.classes.addresses
In the example above, we create User and Address
model classes which will be populated with the columns and
relationships from the users and addresses tables
in the database.
Both User and Address will have all of the standard SQLAthanor methods
and functionality. BUT! They won’t have any serialization/de-serialization
configured.
Before you start working with your models, you can configure their
serialization/de-serialization using either a
declarative approach using
.set_attribute_serialization_config()
or a meta approach by setting the __serialization__ attribute directly:
User.set_attribute_serialization_config('email_address',
supports_csv = True,
supports_json = True,
supports_yaml = True,
supports_dict = True)
User.set_attribute_serialization_config('password',
supports_csv = (True, False),
supports_json = (True, False),
supports_yaml = (True, False),
supports_dict = (True, False),
on_deserialize = my_encryption_function)
User.__serialization__ = [
{
'name': 'email_address',
'supports_csv': True,
'supports_json': True,
'supports_yaml': True,
'supports_dict': True
},
{
'name': 'password',
'supports_csv': (True, False),
'supports_json': (True, False),
'supports_yaml': (True, False),
'supports_dict': (True, False),
'on_deserialize': my_encryption_function
}
]
Both snippets of code above tell the User model to include users.email_address
in both serialized output, and to expect it in de-serialized input. It also tells
the User model to never serialize the users.password column, but to
expect it in inbound data to de-serialize.
See also
Generating SQLAlchemy Tables…¶
…from Serialized Data¶
New in version 0.3.0.
If you are not using SQLAlchemy’s
Declarative ORM
but would like to generate SQLAlchemy Table
objects programmatically based on serialized data, you can do so by importing the
SQLAthanor Table object and calling a
from_<format>() class method:
from sqlathanor import Table
# Assumes CSV data is in "csv_data" and a MetaData object is in "metadata"
csv_table = Table.from_csv(csv_data,
'tablename_goes_here',
metadata,
'primary_key_column',
column_kwargs = None,
skip_nested = True,
default_to_str = False,
type_mapping = None)
from sqlathanor import Table
# Assumes JSON string is in "json_data" and a MetaData object is in "metadata"
json_table = Table.from_json(json_data,
'tablename_goes_here',
metadata,
'primary_key_column',
column_kwargs = None,
skip_nested = True,
default_to_str = False,
type_mapping = None)
from sqlathanor import Table
# Assumes YAML string is in "yaml_data" and a MetaData object is in "metadata"
yaml_table = Table.from_yaml(yaml_data,
'tablename_goes_here',
metadata,
'primary_key_column',
column_kwargs = None,
skip_nested = True,
default_to_str = False,
type_mapping = None)
from sqlathanor import Table
# Assumes dict object is in "dict_data" and a MetaData object is in "metadata"
dict_table = Table.from_dict(dict_data,
'tablename_goes_here',
metadata,
'primary_key_column',
column_kwargs = None,
skip_nested = True,
default_to_str = False,
type_mapping = None)
… from Pydantic Models¶
If you are not using SQLAlchemy’s
Declarative ORM
but would like to generate SQLAlchemy Table
objects programmatically based on Pydantic models, you can do so
by importing the SQLAthanor Table class and calling
the from_pydantic() class
method:
from pydantic import BaseModel
from sqlathanor import Table
# Define Your Pydantic Models
class PydanticWriteModel(BaseModel):
id: int
username: str
email: str
password: str
class PydanticReadModel(BaseModel):
id: int
username: str
email: str
# Create Your Table
pydantic_table = Table.from_pydantic([PydanticWriteModel, PydanticReadModel],
tablename = 'my_tablename_goes_here',
primary_key = 'id')